


Something new is happening in customer research. Companies are buzzing about using AI to simulate their customers. Startups are pitching “synthetic users” and “digital twins.” Enterprises are running pilots with AI personas. Everyone’s excited about the possibility of instant, scalable customer insights without the cost and complexity of traditional research.
Digital twins, synthetic users, synthetic personas promise to transform the research industry, dramatically lowering research costs as well as:
- Accelerating iterative testing: Enabling rapid iteration cycles without the logistical overhead of traditional research
- Extending research lifespan: Maximizing the value of expensive qualitative research by making insights accessible long after the original study concludes
- Democratizing research insights: Making customer perspectives available to teams who typically don’t have direct access to research participants
- Testing edge cases and scenarios: Exploring hypothetical situations that would be difficult or expensive to test with real participants
- Reducing participant burden and fatigue: Minimizing the need to repeatedly recruit and engage the same customers for follow-up questions
- Providing a privacy-safe way of exploring sensitive topics with audiences
- Maintaining continuity: Preserving institutional knowledge when researchers leave or between research cycles
At the same time, there has also been scathing criticism of the field.
- Creating “word salad” without meaning: Statistical text prediction that looks plausible but has no actual understanding, forcing teams to infer meaning and enabling confirmation bias
- Amplifying embedded discrimination: Baking in biases from scraped internet data that contains discrimination and represents only a narrow slice of humanity
- Missing the deeper “why”: Failing to capture interior cognition—the inner thinking, emotional reactions, and personal rules that only emerge through human listening
The thing is: nobody really knows what works yet. The terminology is confusing—vendors use the same words to mean wildly different things. The evidence is preliminary—most academic studies are less than two years old. And while the promise is enormous, the reality is still being figured out in real-time.
After analyzing 16 research papers on the topic, we’re going to explain what these AI customer research tools actually do, how they’re different from each other, where the research shows they work, where they fall flat, and how to make smart decisions about using them.
- What We’re Actually Talking About
The fundamental goal of AI in customer research is straightforward: reproduce human behavior not to automate tasks, but to observe that behavior. Research labs and companies are using different methodologies to create simulations of users and clients, then observing these simulations to draw conclusions about what humans might actually do—at a fraction of the cost and effort of observing actual humans.
These simulations go by many names: Generative Agents (GAs), LLM Social Simulations, or perhaps most accurately—AI Automatons: AI systems specifically designed to imitate humans for observation and analysis.
AI automatons – LLM-based simulations of human behavior build for observation and analysis, have the potential to reshape research in every conceivable vertical. But do they actually work?
The market implications are staggering. Political campaigns test messaging with AI voters. Fortune 500 companies simulate customer reactions before product launches. UX teams run hundreds of synthetic user sessions in the time it once took to schedule five real participants. Pharmaceutical companies explore synthetic patients for early-stage trial design. The AI automaton sector isn’t just growing—it’s fundamentally reshaping how organizations understand and predict human behavior.
But do they actually work? And more importantly, how do they work? To answer these questions, we need to understand the mechanics: how these tools are built, what they can actually do, and what distinguishes truly different approaches from mere terminology differences.
The market implications are staggering. Every year, the world spends 130 billion dollars in market research. What began in academic psychology labs—where researchers experiment with replicating costly human studies—has exploded across industries. Political campaigns are using AI automatons to test messaging and predict voter behavior. Fortune 500 companies are deploying them to simulate customer reactions before product launches. UX teams are running hundreds of synthetic user sessions in the time it once took to schedule five real participants. Market research firms are offering “instant focus groups” powered by digital twins. Even pharmaceutical companies are exploring synthetic patients for early-stage trial design. The AI automaton sector isn’t just growing—it’s fundamentally reshaping how organizations understand and predict human behavior across every domain where that understanding creates competitive advantage.
But what kind of simulations exist, and most importantly: do they work?
- How LLM Automatons Work: The Foundation

Understanding how these tools function starts with two simple phases: construction (feeding data into an LLM to create the automaton) and use (querying it for insights). The magic—and the limitations—emerge from three critical questions: What data do we use? What can we ask? What does the automaton represent?
What Can We Feed the LLM to Construct an Automaton?

Every AI automaton needs raw material anchored in reality. The type and richness of input fundamentally shapes what you can accomplish with the resulting twin.
Census data
Often the starting point for building both synthetic users and personas, it of often additionally enriched with other input sources.
Persona descriptions sit at the most abstract end—generic profiles based on demographics or psychographics.
“35-year-old marketing manager in Boston who values work-life balance.” These don’t capture specific individuals but rather archetypal segments. They’re fastest to create but sacrifice individual-level accuracy.
System or behavioral data captures quantitative footprints—website analytics, purchase histories, navigation patterns, CRM interactions. This tells you what people do without explaining why. Stanford researchers showed that even this “thin” behavioral data, when comprehensive enough, can predict user actions with surprising accuracy. The advantage: you often already have this data. The limitation: it can’t reveal motivations or reasoning.
Survey data provides structured snapshots through standardized questions—demographics, personality traits (Big Five, HEXACO), stated preferences, Likert scales.
The Columbia mega-study constructed digital twins from 500 survey questions covering everything from demographics to cognitive abilities. This creates a comprehensive psychological profile that can be queried for new situations. Survey data sits in the middle: more structured than interviews, richer than behavioral logs.
Written material from the person—emails, social media posts, documents they’ve authored—occupies the qualitative, “by the person” space. This captures voice, reasoning patterns, and implicit knowledge without requiring new research. One company we’ve encountered uses LinkedIn posts and professional writings to build executive digital twins, though accuracy varies with writing volume and authenticity.
Interview transcripts offer the richest input. Park et al.’s landmark study used two-hour qualitative interviews to build 1,052 generative agents that achieved 85% accuracy predicting individual attitudes—significantly outperforming agents built from demographics or simple persona descriptions. The depth matters: these agents could explain their reasoning, reveal tacit knowledge, and maintain consistency across entirely new contexts. When Atypica and Emporia Research conduct 2.5-hour interviews for their digital twins, they’re capturing not just what someone thinks but how they think.
Brain scans represent the most experimental frontier. We know of at least one company, Brainvivo, exploring whether neural activation patterns can inform digital twin construction—essentially asking whether brain imaging could capture decision-making processes that even the person themselves can’t articulate. This remains largely research territory, though it points to the field’s ambitions.
The pattern is clear: richer, more specific input enables more sophisticated querying. A persona built from census data can simulate segment-level preferences. A twin built from two-hour interviews can explain tacit reasoning and generate contextually appropriate ideas. Which brings us to what you can actually do with these automatons.
What Can We Ask an LLM Automaton?

Every application in customer research falls into three core functions:
Every application falls into three categories: clarifying what you already know, simulating new decisions, or generating ideas
1. Clarify and Extend Past Responses
This is about deepening understanding of what you’ve already learned. Ask a digital twin to elaborate on a workflow phase mentioned in interviews, or to explain the why behind a survey response. This includes extracting tacit knowledge—the unstated rules, heuristics, and mental models that experts develop but rarely articulate. It also means modeling behavioral consistency over time: if you’ve interviewed the same people multiple times about brand perception, you can query how their views evolved and what drove those shifts.
Sample questions you might ask:
- “You mentioned frustration with the approval process in our interview—can you walk me through exactly where the bottlenecks happen?”
- “What unwritten rules guide how you evaluate vendors in this category?”
- “Your survey response indicated strong preference for Feature X—what specific problem does that solve in your daily workflow?”
- “How has your view of our brand changed over the past year, and what events or experiences drove that change?”
- “When you said ‘ease of use’ matters most, what does that actually mean in practice for someone in your role?”
- “What do you know from experience that someone new to your job wouldn’t understand yet?”
2. Simulate Decisions in New Scenarios
This is predictive: testing purchase intent for new product concepts, modeling voting behavior for different policy framings, or predicting how users would navigate a redesigned interface. Maier et al. (2025) demonstrated this powerfully—their LLM-based synthetic consumers reproduced purchase intent at 90% of human test-retest reliability across 57 product concepts. You’re projecting known individuals into unknown situations.
Sample questions you might ask:
- “How likely would you be to purchase this product concept at $X price point? What makes it appealing or unappealing?”
- “If we moved this feature from the main menu to settings, would that solve your navigation concerns?”
- “How would your procurement committee evaluate these three competing solutions?”
- “Would you recommend this to a colleague? Why or why not?”
- “What concerns would your CFO raise about adopting this solution?”
- “How would this change your current workflow, and would that change be welcome?”
3. Generate New Ideas
This moves beyond prediction to co-creation. Brainstorm with a digital twin as you would a real stakeholder, getting reactions to early concepts, exploring “what if” scenarios, or having them suggest solutions from their perspective. Researchers studying persona-based chatbots (Gu et al., 2025) found that designers could use synthetic personas for rapid feedback loops—though consistency remains a concern we’ll explore later.
Sample questions you might ask:
- “Given your frustrations with current solutions, what would your ideal product look like?”
- “How would someone in your role approach solving [specific problem]?”
- “What features are we overlooking that would make this genuinely useful to you?”
- “If you were designing this for your team, what would you prioritize?”
- “What creative workarounds have you developed for limitations in existing tools?”
- “How might this concept need to adapt for different departments in your organization?”
These three functions aren’t equally applicable to all types of automatons, which becomes clearer when we examine the different categories of tools available.
- Digital Twins vs Augmented Personas vs Synthetic Users: What’s Actually Different?

The terminology confusion isn’t merely a communication problem. When vendors use identical terms to describe fundamentally different capabilities, organizations make poor purchasing decisions and set unrealistic expectations. Let’s establish what actually distinguishes these approaches.
Digital Twins: Individual-Level Simulation

A digital twin is an AI simulation representing one specific person, built from real research data about that individual. One human, one twin. This 1:1 mapping is what separates digital twins from everything else.
The Columbia mega-study (Peng et al., 2025) is a treasure trove for digital twin-related findings. They tested dozens of propositions using 2,000 digital twins across 19 studies. Each twin was constructed from 500 questions about their specific human counterpart—demographics, personality traits (279 questions from 19 different tests), cognitive abilities, and economic preferences. The result? Digital twins achieved ~75% individual-level accuracy, with their real advantage showing in correlation (~0.2): they captured relative differences between individuals better than demographic-only approaches.
Digital twins can do all three core functions—clarify past responses, simulate new decisions, and generate ideas—because they’re grounded in rich individual-level data.
When Stanford researchers built twins from two-hour interviews (Park et al., 2025), they could ask these agents to explain tacit reasoning, predict behavior in controlled experiments, and even generate novel responses that matched their human counterparts’ personality traits.
The research shows a clear pattern: richer input data unlocks more functions. Digital twins excel at extending and clarifying past responses precisely because there’s substantial past data to work with. They can simulate new decisions because their training captures how specific individuals think, not just demographic averages. And they can generate contextually appropriate ideas because they’ve internalized individual reasoning patterns. On the other hand, digital twins also exhibit several blind spots and biases, which we’ll discuss later.
Synthetic Personas: Segment-Level Simulation
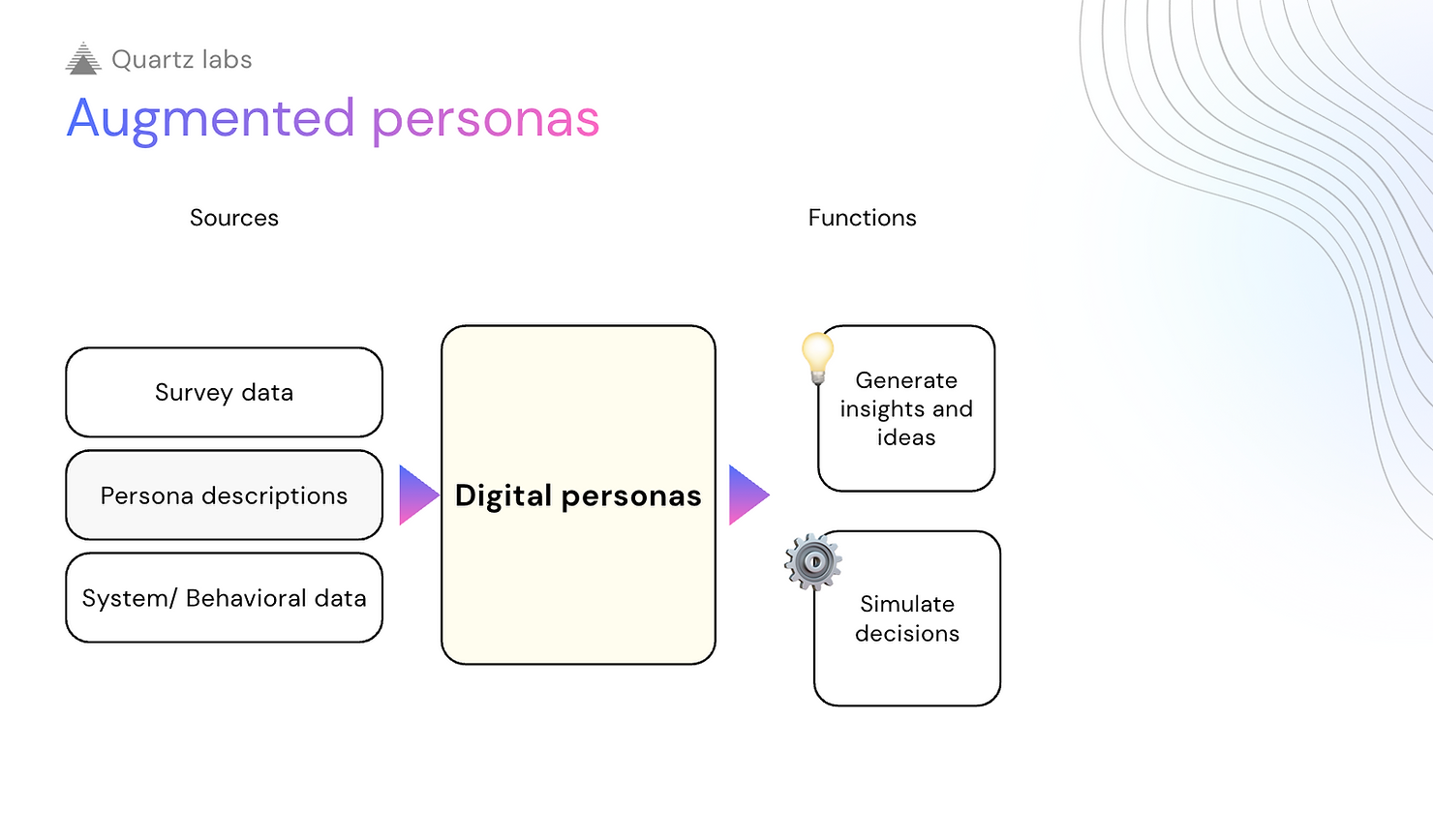
Synthetic personas simulate entire segments, not individuals. They’re built from aggregated data or simply by prompting an LLM to adopt a demographic/psychographic profile: “You’re a 35-year-old marketing manager in Boston who values work-life balance.”
Without individual-level grounding, synthetic personas can only reliably do two of the three core functions—simulating decisions and generating ideas. They can’t meaningfully clarify past responses because there are no specific past responses to clarify. Research by Gu et al. (2025) studying persona-based chatbots found that while designers could use them for rapid feedback, there was greater variation in how designers perceived the persona’s attributes—the personas weren’t consistent enough to serve as reliable extensions of specific research findings.
This makes synthetic personas potentially valuable for early-stage exploration and team education, but risky for decisions requiring individual-level accuracy or consistency over time.
Synthetic Users: Task-Specific Digital Twins
Synthetic users are a specialized subcategory of digital twins—ones focused exclusively on simulating task completion and interface interactions rather than broad human behavior. They’re digital twins optimized for the second function: simulating decisions in new scenarios, but narrowed specifically to technical and interaction decisions.
Lu et al. (2025) demonstrated this with UXAgent, a system generating thousands of LLM agents that interact with actual web environments through browser automation. These synthetic users successfully navigated e-commerce sites, completed purchase flows, and identified usability issues—essentially running digital twins through predefined task sequences.
Because they’re narrowly scoped, synthetic users typically require less rich input data—often just demographic information plus task instructions. But this efficiency comes with clear boundaries: don’t use them for strategic decisions about product-market fit or value propositions.
Synthetic Data: Not Actually an Automaton
Synthetic data deserves clarification because it’s fundamentally different from digital twins, personas, or synthetic users. It’s not an interactive automaton at all—it’s artificially generated information that mirrors statistical properties of real data.
The most practical application: augmented synthetic data. Collect a small sample of real research (15 CTO interviews), then use AI to generate additional responses matching those statistical patterns, expanding your sample to 200+ for quantitative analysis. This is a data augmentation technique, not a simulation of human thinking.
Now that we’ve established what these tools are and how they work in theory, what does the research actually show about when they succeed and when they fail? The answer is more nuanced than marketing materials suggest.
- What Actually Works: Evidence by Function
Before examining what works, we need to address a fundamental question: what does “success” even mean for digital twins and synthetic personas?
The meaning of success
What counts as success? 85% individual accuracy, or just beating educated guesswork?
The research literature reveals three distinct standards:
Individual-level accuracy: Can the automaton replicate what a specific person would say or do? The Columbia mega-study found ~75% accuracy, while Stanford’s interview-based agents achieved 85% normalized accuracy.
Aggregate correlation: Can automatons capture relative differences between people, even if absolute predictions aren’t perfect? Digital twins achieved correlations around 0.2, outperforming traditional machine learning benchmarks that would require collecting data from ~180 additional participants.
Better than the alternative: Are automatons more accurate, faster, or cheaper than however we did things before—often educated guesswork? For many commercial applications, this pragmatic standard matters most. Crucially, almost no research has focused on this metric (which admittedly, would be methodologically challenging).
With these standards in mind, the research reveals a clear pattern: success depends on matching the right tool to the right function. Let’s examine what the evidence shows for each of our three core functions.
Overview of the findings
Function 1: Clarifying and Extending Past Responses

This is where individual-level digital twins show their clearest advantage—and where personas and synthetic users simply can’t compete.
Park et al.’s (2025) Stanford study demonstrated this powerfully. When interview-based agents were asked to explain their reasoning on General Social Survey questions, they could articulate consistent positions grounded in their source interviews. Ask about political views, and they could explain why they held those positions, referencing specific life experiences mentioned in their foundational interview. This is clarification in action—deepening understanding of already-collected data.
Digital twins can’t simulate ignorance: they answered 99.88% of questions correctly while humans scored only 51.75%.
The Columbia study (Peng et al., 2025) revealed something equally important: this function has limits. When asked about topics only tangentially related to the original survey questions, accuracy dropped. Digital twins built from 500 demographic and personality questions struggled to explain nuanced political positions—they could provide an explanation, but not necessarily their human counterpart’s explanation. The tacit knowledge wasn’t there because it hadn’t been captured in the first place.
The same study revealed an even more fundamental limitation: digital twins can’t simulate human ignorance. When asked to identify definitions of marketplace fees (like “surcharge”), twins answered 99.88% correctly while humans scored only 51.75%. The twins were quasi-omniscient—they couldn’t suppress the correct information to simulate genuine human misconceptions or knowledge gaps. This matters because sometimes you need to understand what customers don’t know, not just what they do.
Practical implication: Use digital twins to extend qualitative research within its original domain. If you interviewed CTOs about cloud infrastructure decisions, their twins can clarify procurement processes, explain technical requirements, or elaborate on vendor evaluation criteria. But don’t expect them to reliably explain their consumer purchasing behavior—that wasn’t in the training data. And don’t expect them to reveal knowledge gaps or misconceptions—they know too much.
Function 2: Simulating Decisions in New Scenarios

This is the most commercially validated function, working across multiple tool types with distinct strengths.
Consumer Decisions: Maier et al. (2025) tested LLM-based synthetic consumers on 57 personal care product concepts with 9,300 human responses. Using Semantic Similarity Rating (converting textual responses to Likert distributions), synthetic consumers achieved 90% of human test-retest reliability with KS similarity > 0.85. Critically, they correctly ranked which products would be more versus less appealing—the relative ordering that drives portfolio decisions.
Methodology matters: Direct Likert elicitation failed catastrophically, producing unrealistically narrow distributions. LLMs needed to explain reasoning first, then map to numerical scales. This suggests these tools work best simulating how people decide, not just what they decide.
Synthetic consumers achieved 90% test-retest reliability—but only when methodology avoided the LLM’s regression-to-mean bias.
Interface Interactions: Synthetic users shine because the task is narrow. Lu et al.’s (2025) UXAgent successfully navigated e-commerce sites, identified broken flows, and caught usability issues before human testing. These specialized digital twins achieved their purpose: catching technical problems cheaply.
Where Decision Simulation Fails: The Columbia mega-study tested twins across multiple decision contexts, revealing systematic patterns in where they struggle:
Symbolic and luxury consumption: When evaluating a luxury sweater with or without digital certification (a “digital passport”), humans perceived higher value with the certification—an exclusivity effect. Digital twins showed no response to the certification, completely missing the symbolic consumption dynamic. They understand functional value but fail at status signaling.
Workplace preferences: Twins systematically over-estimated preferences for pro-social attributes (sustainability, ESG, work-life balance) and under-estimated instrumental career attributes (firm prestige, career development). They appear more virtuous than their human counterparts actually are.
News sharing decisions: When rating likelihood of sharing news articles, twins placed significantly more weight on source trustworthiness and political lean than humans did. They exhibited hyper-rational behavior, incorporating information that humans often overlook or deprioritize.
Consumer minimalism: Twins correctly aligned preferences with Consumer Minimalism Scale scores (high scorers preferred minimalist environments), but exhibited more extreme and polarized attitudes than their human counterparts.
The pattern is clear: digital twins excel at analytical decisions (product evaluation, task completion) but struggle with social identity, cultural signaling, symbolic value, and emotionally complex trade-offs. They’re also systematically more rational and knowledge-driven than real humans.
Function 3: Generating New Ideas

This function reveals a paradox: digital twins generate higher-quality ideas with less diversity.
The Columbia mega-study asked both twins and humans to generate ideas for health-focused smartphone applications. Human evaluators rated the twins’ ideas as significantly more creative than human-generated ideas. But there’s a catch: twin ideas showed lower variance in creativity ratings—they were consistently good but less diverse. This suggests twins excel at generating polished, well-structured ideas but may miss the unexpected, unconventional concepts that sometimes drive breakthrough innovation.
The study also revealed systematic bias in how twins evaluate ideas. When shown ideas from human or AI sources and told which was which, humans displayed “AI aversion”—they rated human ideas higher. Digital twins showed the opposite: “human aversion”—they rated human ideas lower than AI-generated ideas. This inverted bias matters if you’re using twins to evaluate or prioritize concepts.
Gu et al. (2025) confirmed the consistency concern when studying designers working with synthetic persona chatbots. While designers could brainstorm effectively, they experienced greater variation in perceived attributes—different designers came away with different understandings of the same persona’s preferences and priorities. The personas weren’t stable enough to serve as reliable extensions of specific research findings.
Practical implication: Use digital twins for early-stage exploration to generate polished concept variations. But expect less wild divergence than human brainstorming might produce, be aware of pro-AI bias when evaluating ideas, and validate concepts with real stakeholders before committing resources.
- The Limitations: where digital twins, augmented personas, ecc. struggle
Every technology has boundaries. Here’s what these tools can’t do, based on current research and practice.

Across all three functions, certain limitations appear consistently:
The Hyper-Rational Problem: A pattern emerges across multiple studies: digital twins are systematically more rational, knowledgeable, and “virtuous” than their human counterparts. They know marketplace fees that humans don’t (99.88% vs 51.75% accuracy). They weight source trustworthiness in news sharing more than humans do. They over-value pro-social workplace attributes. This isn’t noise—it’s a systematic bias toward rationality that misses how humans actually use heuristics, make emotional decisions, and have real knowledge gaps.
Demographic Bias: Digital twins are systematically more accurate for higher education, higher income, and moderate political views. Whose perspectives dominate LLM training data matters.
Political Contexts: Twins performed worse in political domains, often stereotyping based on ideology. Li et al. (2025) found increasingly detailed personas paradoxically shifted left—training data bias in action.
Variance Compression: Twins produce narrower response distributions than humans, missing outliers and edge cases that sometimes drive product innovation. Their creativity scores are higher on average but show less variance.
Under-Represented Populations: Accuracy drops for the exact populations you’d most want to understand better—those currently underserved or underrepresented.
Understanding these capabilities and limitations in the abstract is one thing. Choosing actual vendors is another. The commercial landscape has evolved rapidly, but the marketing often obscures which platforms genuinely excel at which functions. Here’s how to cut through the noise.
- Commercial Offerings: What’s out there to get your own Digital Twins, Synthetic Personas, etc.
The solutions below represent a snapshot of what’s currently available—not an exhaustive list. These providers are at different stages of maturity, each with their own arguments for why their approach delivers the best results. Keep in mind that all of them are relatively new, since the entire field of AI-powered customer research has only emerged in the past couple of years.
The market organizes itself along two key dimensions: whether you’re creating digital twins (specific individuals) or synthetic personas (representative segments), and whether you’re looking for on-demand platforms or custom-built solutions.
Custom-Built Digital Twins
These providers create high-fidelity twins of specific individuals, typically requiring interviews or substantial existing research data:
The Mirror: Transforms your existing B2B research into interactive twins. Works with interview transcripts, surveys, and behavioral data. Privacy-first architecture optimized for complex B2B buying dynamics.
Atypica: Uses 2.5-hour interviews grounded in morphological psychology to achieve 85% behavioral consistency. Offers both proprietary twins and an existing library. Particularly strong at surfacing and clarifying tacit knowledge.
Soulmates AI: Recruits real people, then builds high-fidelity twins using HEXACO personality frameworks with 93% fidelity scores. Full-service approach works especially well for gaming companies and digital-native communities.
Emporia Research: Focuses on LinkedIn-verified B2B professionals through 2.5-hour interviews, delivering 92.5% data quality improvement over traditional methods. Can provide access to either the real professionals or their digital twins. Currently, digital twins are available specifically for accountants.
Have $50K+ in existing research gathering dust? That’s your raw material for digital twins
On-Demand Personas & Twins
These platforms let you start testing immediately without custom development:
Evidenza: Creates B2B “synthetic buyers” from analyst reports and public data sources. Functions as sophisticated segment-level personas (despite positioning as twins). Delivers 88% correlation with real behavior in 3-12 hours versus traditional 3-12 months.
SyntheticUsers: Provides synthetic personas (segment-level representations, despite the “users” name) through a multi-agent FFM framework with 95%+ alignment scores. DIY platform enables rapid testing and iteration.
Ditto: Offers population-level personas calibrated to census data and updated with real-time news. Statistically grounded approach with self-serve platform access.
Specialized: Task-Specific Tools
UXAgent platforms: Navigate web environments, complete specific tasks, and identify usability issues. Purpose-built for interface testing rather than strategic decision-making.
Specialized: Task-Specific
UXAgent platforms: Navigate web environments, complete tasks, identify usability issues. Not designed for strategic decisions.
- Making the Right Choice: A Decision Framework
To conclude, here is Match tools to your specific situation using these practical criteria:
Do You Have Existing Research Data?
YES – Rich qualitative or quantitative data:
- Choice: Custom-built digital twins (The Mirror, Atypica, Emporia)
- Why: Multiply value of research already paid for
- Timeline: Days to weeks
NO – Starting from scratch:
- Quick directional: On-demand synthetic personas (SyntheticUsers, Ditto)
- High-fidelity: Full-service custom (Soulmates AI handles recruiting)
- Timeline: Immediate (personas) to weeks (custom)
Do You Have a Clear Audience or Still Exploring?
YES – Defined audience:
- Narrow/specialized (B2B executives, domain experts): Custom twins (Emporia, The Mirror, Soulmates AI)
- Broad consumer segments: On-demand personas if you can define demographics clearly
NO – Still exploring:
- On-demand personas for rapid hypothesis testing
- Validate promising segments with real research, then build twins
What’s Your Research Goal?
Exploratory: Synthetic personas (fast, cheap iteration) Validation: Digital twins from existing research OR new interviews + twins OR Evidenza (B2B) Brainstorming: Synthetic personas or lightweight twins (unlimited follow-ups)
B2B or B2C Context?
B2B (complex buying, hard-to-reach executives):
- With data: The Mirror, Emporia
- Without: Evidenza (fast), Soulmates AI (custom)
B2C (consumer, mass market):
- High volume: SyntheticUsers platform
- High stakes/niche: Custom twins (Atypica, Soulmates AI)
Generic vs Specialized Audience?
Generic, broad: Census-calibrated personas (Ditto), standard platforms Narrow, specialized, experts: Custom digital twins essential (generic LLMs fail for expert domains)
The Path Forward
The research validates these technologies within clear boundaries. Digital twins from two-hour interviews achieve 85% normalized accuracy. Synthetic consumers reproduce purchase intent at 90% of test-retest reliability. They outperform traditional ML requiring 180+ additional participants.
But they also systematically underrepresent certain populations, struggle with political contexts and identity-heavy decisions, produce narrower variance than humans, and miss emerging needs.
Organizations seeing real value aren’t choosing between humans and AI. They layer approaches: quality research as foundation, digital twins for daily accessibility, synthetic personas for rapid exploration, synthetic users for technical validation, regular human research for grounding.
The technology works. The question is whether we use it wisely: investing in quality research first, extending thoughtfully, validating continuously, staying humble about limitations.
About The Mirror: We transform your existing B2B research into interactive digital twins, extending the value of qualitative interviews, surveys, and customer data you’ve already collected. Learn more
Further Reading & Sources
On Digital Twins:
- Kim, J., & Lee, B. (2024). “AI-Augmented Surveys: Leveraging Large Language Models for Opinion Prediction” – Stanford University study on digital twin accuracy and validation
- Nielsen Norman Group (2025). “Evaluating AI-Simulated Behavior: Insights from Three Studies on Digital Twins and Synthetic Users”
On Synthetic Data:
- Conversion Alchemy (2025). “The State of Synthetic Research in 2025” – comprehensive industry analysis of synthetic data applications and limitations
- Solomon Partners (2025). “Synthetic Data is Transforming Market Research” – includes EY case study showing 95% correlation
On Best Practices:
- McKinsey (2024). “Digital Twins and Generative AI: A Powerful Pairing” – enterprise implementation guidance and ROI analysis
- Verve (2025). “Digital Twins, Synthetic Data, and Audience Simulations” – comparative analysis of different approaches
Must-read papers:
- Adornetto, C., Mora, A., Hu, K., Garcia, L. I., Atchade-Adelomou, P., Greco, G., Pastor, L. A. A., and Larson, K. (2025). Generative Agents in Agent-Based Modeling: Overview, Validation, and Emerging Challenges.
- Anthis, J. R., Liu, R., Richardson, S. M., Kozlowski, A. C., Koch, B., Brynjolfsson, E., Evans, J., and Bernstein, M. S. (2025). Position: LLM Social Simulations Are a Promising Research Method. In Proceedings of the 42nd International Conference on Machine Learning, Vancouver, Canada. PMLR 267.
- Gu, H., Chandrasegaran, S., Lloyd, P. (2025). Synthetic users: insights from designers’ interactions with persona-based chatbots. Artificial Intelligence for Engineering Design, Analysis and Manufacturing, 39, e2, 1–17. https://doi.org/10.1017/S0890060424000283
- Kang, T., Thorson, K., Peng, T.-Q., Hiaeshutter-Rice, D., Lee, S., Soroka, S. (2025). EMBRACING DIALECTIC INTERSUBJECTIVITY: COORDINATION OF DIFFERENT PERSPECTIVES IN CONTENT ANALYSIS WITH LLM PERSONA SIMULATION. A PREPRINT, February 5, 2025.
- Lee, K., Kim, S. H., Lee, S., Eun, J., Ko, Y., Jeon, H., Kim, E. H., Cho, S., Yang, S., Kim, E., Lim, H. (2025). SPeCtrum: A Grounded Framework for Multidimensional Identity Representation in LLM-Based Agent.
- Li, A., Chen, H., Namkoong, H., Peng, T. (2025). LLM Generated Persona is a Promise with a Catch.
- Lu, Y., Yao, B., Gu, H., Huang, J., Wang, Z. (J.), Li, Y., Gesi, J., He, Q., Li, T. J.-J., Wang, D. (2025). UXAgent: An LLM-Agent-Based Usability Testing Framework for Web Design. In Extended Abstracts of the CHI Conference on Human Factors in Computing Systems (CHI EA ’25), April 26-May 1, 2025, Yokohama, Japan. https://doi.org/10.1145/3706599.3719729
- Maier, B. F., Aslak, U., Fiaschi, L., Rismal, N., Fletcher, K., Luhmann, C. C., Dow, R., Pappas, K., and Wiecki, T. V. (2025). LLMs Reproduce Human Purchase Intent via Semantic Similarity Elicitation of Likert Ratings.
- Mansour, S., Perelli, L., Mainetti, L., Davidson, G., D’Amato, S. (2025). PAARS: Persona Aligned Agentic Retail Shoppers.
- Olteanu, A., Barocas, S., Blodgett, S. L., Egede, L., DeVrio, A., Cheng, M. (2025). AI Automatons: AI Systems Intended to Imitate Humans. Manuscript submitted to ACM.
- Park, J. S., Zou, C. Q., Shaw, A., Hill, B. M., Cai, C., Morris, M. R., Willer, R., Liang, P., and Bernstein, M. S. (2024). Generative Agent Simulations of 1,000 People. arXiv: 2411.10109.
- Peng, T., Gui, G., Merlau, D. J., Fan, G. J., Sliman, M. B., Brucks, M., Johnson, E. J., Morwitz, V., Althenayyan, A., Bellezza, S., Donati, D., Fong, H., Friedman, E., Guevara, A., Hussein, M., Jerath, K., Kogut, B., Kumar, A., Lane, K., Li, H., Perkowski, P., Netzer, O., Toubia, O. (2025). A Mega-Study of Digital Twins Reveals Strengths, Weaknesses and Opportunities for Further Improvement.
- Schroeder, H., Aubin Le Quéré, M., Randazzo, C., Mimno, D., and Schoenebeck, S. (2025). Large Language Models in Qualitative Research: Uses, Tensions, and Intentions. In CHI Conference on Human Factors in Computing Systems (CHI ’25), April 26-May 1, 2025, Yokohama, Japan. ACM, New York, NY, USA, 17 pages. https://doi.org/10.1145/3706598.3713726
- Wang, P., Zou, H., Chen, H., Sun, T., Xiao, Z., Oswald, F. L. (2025). Personality Structured Interview for Large Language Model Simulation in Personality Research.
- Wang, Q., Wu, J., Tang, Z., Luo, B., Chen, N., Chen, W., He, B. (2025). What Limits LLM-based Human Simulation: LLMs or Our Design? arXiv preprint arXiv:2501.08579.
- Yang, L., Luo, S., Cheng, X., Yu, L. (2025). Leveraging Large Language Models for Enhanced Digital Twin Modeling: Trends, Methods, and Challenges. Preprint submitted to Arxiv Preprint March 5, 2025.
- Weingram A., Cui C., Lin S., Munoz S., Jacob T., Viers J. and Lu X. (2025). A definition and taxonomy of digital twins: case studies with machine learning and scientific applications. Front. High Perform. Comput. 3:1536501. doi: 10.3389/fhpcp.2025.1536501.
